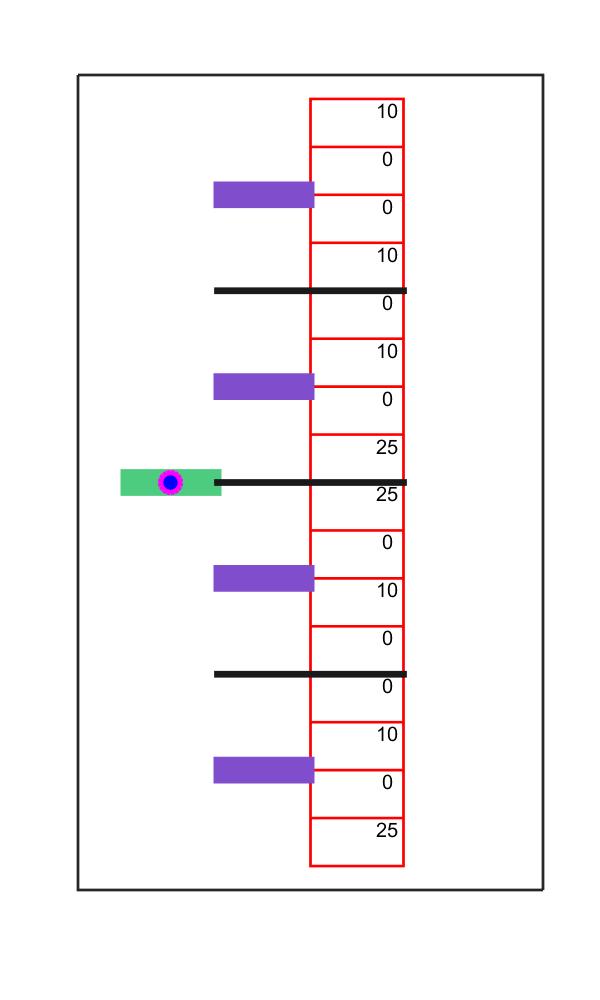
In this example I replicated task and model described in Glasher et al. 2010 (available here: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2895323/ ). The task is essentially a two armed bandit with probabilistic outcomes (distribution of probabilities: 0.7-0.3), played on two levels, so that the agent has to perform 2 choices in sequence (left or right), to reach a reward, virtually following the branches of a binary decision three. The rewards are static and they are represented by values of 0, 10 and 25.
If the behavior of the agent is controlled only by the model-free component (e.g. SARSA, see: example 1 or example 2), the agent will be able to discriminate correctly which action is associated with the highest expected values, at the time of the second choice. However, the model-free control alone would consider both actions at the first level as equally valuable, as if the overall rewards that can be reached after either initial choice were the same.5
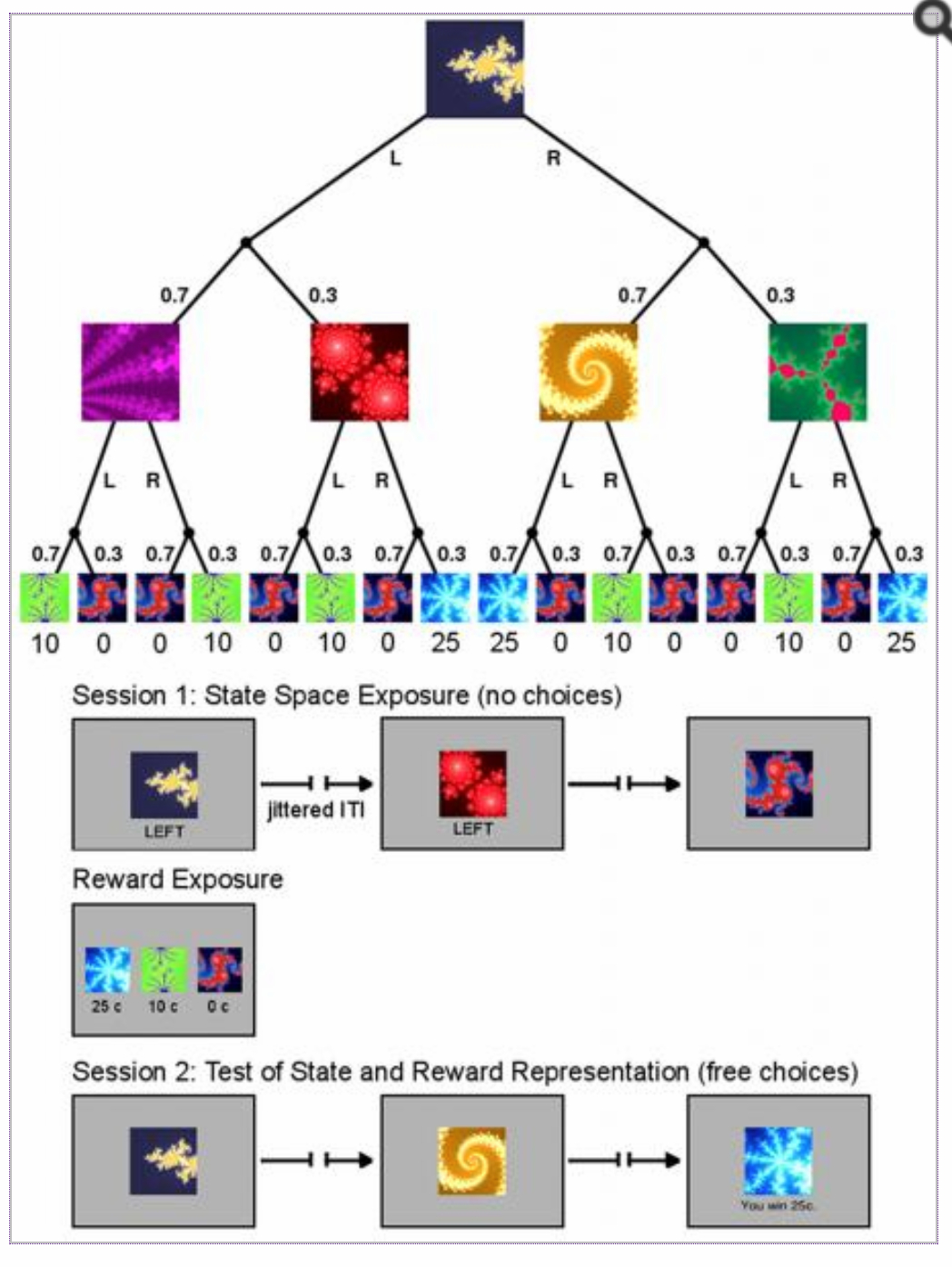
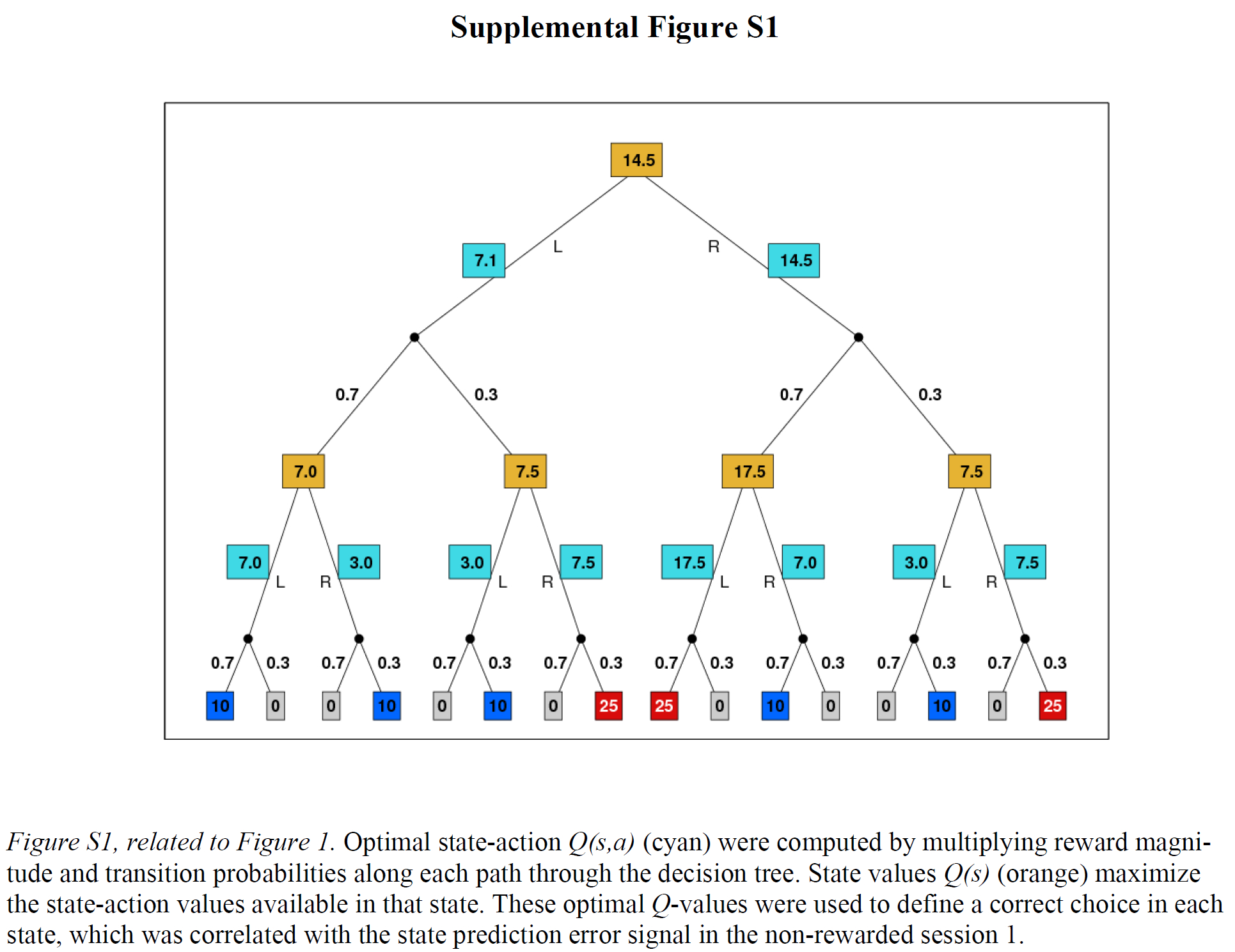
Thus, to solve the task it is necessary to rely on a hybrid control system that integrates the classic model-free with a decision making system capable of generating a correct map of state-action associations, that includes the different probabilities to navigate either task. This component is usually termed model-based, as it generates a model of the world on which choices are then based.
You can download the whole code here (zip archive), where I have also added a graphical live representation (see below) of the choices performed by the agent, to allow easy track of the behaviour. Convergence towards optimal behavior across a short number of trial is not always found.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
clear all close all time=250; epsilon=0.01; alpha=0.1; gamma=0.5; eta=0.1; temp=0.1; action=zeros(time,1); rew=zeros(time,1); all_rewards=[0 0 0 0 0 10 0 0 10 0 10 0 25 25 0 10 0 0 10 0 25]; position=zeros(time,1); c1=zeros(time,1); c2=zeros(time,1); position(1,:)=1; c1(1)=1; c2(1)=8.5; n_actions=2; n_states=21; for k=1:n_states Qasv_s(k,:)=ones(1,n_actions)/n_actions; Qfwd(k,:)=ones(1,n_actions)/n_actions; Qhyb(k,:)=ones(1,n_actions)/n_actions; end cnt=0; for k=1:5 for ki=1:n_actions for kj=1:2 cnt=cnt+1; trans(cnt,:)=[k, ki, cnt+1, 0.5]; end end end trans_count=trans; trans_count(:,4)=trans_count(:,4)-0.5; fig=figure('Name', '2CHOICE_MARKOV', 'Position', [100 0 600 1000]); arena_builder_2step h = hgtransform('Parent',gca); plot(-0.5,-0.5,'o','LineWidth', 4, 'color', 'm','MarkerSize', 15,'MarkerFaceColor', 'b', 'Parent',h) m1 = makehgtform('translate',c1(1),c2(1),0); h.Matrix = m1; drawnow trial=0; for ij=2:time %determine behavior if rand(1)<=epsilon %random exploration action(ij)=randi(2); elseif position(ij-1)<6 %SOFTMAX exploration sms1=softmaxselection(Qhyb((position(ij-1)),:), temp); action(ij)=sms1{1}; else action(ij)=randi(2); end %compute position and reward if position(ij-1)>5 position(ij)=1; c1(ij)=1; c2(ij)=8.5; else comp_position end %compute value %MODEL-FREE Update: SARSA sms2=softmaxselection(Qasv_s(position(ij-1),:),temp); sarsaval=epsilon*(mean(Qasv_s(position(ij-1),:))) + (1-epsilon)*sms2{3}; Qasv_s(position(ij-1), action(ij))= ... Qasv_s(position(ij-1), action(ij)) + alpha*(rew(ij) + ... gamma*(sarsaval) - Qasv_s(position(ij-1), action(ij))); % FORWARD Update: the internal model of transitions prob=[0 0]; potential_rew=[0 0]; for tr=1:length(trans(:,1)) if trans(tr,1:3)==[position(ij-1), action(ij), position(ij)] delta_SPE=1-trans(tr,4); trans(tr,4)=trans(tr,4)+eta*delta_SPE; trans_count(tr,4)=trans_count(tr,4)+1; if tr<20 && trans(tr,3)<trans(tr+1,3) && trans(tr,2)==trans(tr+1,2) trans(tr+1,4)=trans(tr+1,4)*(1-eta); prob=[trans(tr,4) trans(tr+1,4)]; potential_rew=[all_rewards(trans(tr,3)) all_rewards(trans(tr+1,3))]; elseif tr>1 && trans(tr,3)>trans(tr-1,3) && trans(tr,2)==trans(tr-1,2) trans(tr-1,4)=trans(tr-1,4)*(1-eta); prob=[trans(tr-1,4) trans(tr,4)]; potential_rew=[all_rewards(trans(tr-1,3)) all_rewards(trans(tr,3))]; end break end end %Q forward model Qfwd(position(ij-1), action(ij))=sum(prob.*(potential_rew+ max(Qfwd(position(ij,:))))); %HYBRID wt=1*exp(-0.02*ij); Qhyb(position(ij-1), action(ij))=wt*Qfwd(position(ij-1), action(ij))+... (1-wt)*Qasv_s(position(ij-1), action(ij)); %GRAPHICAL PART plot(-0.5,-0.5,'o','LineWidth', 4, 'color', 'm','MarkerSize', 15,'MarkerFaceColor', 'b', 'Parent',h) m1 = makehgtform('translate',c1(ij),c2(ij),0); h.Matrix = m1; %t1; set(gca,'YTick',[]) set(gca,'XTick',[]) drawnow pause(0.1) disp('To speed up, erase the pause among intervals'); end |